


.svg)

contact@blackcoffeerobotics.com

India, USA
Traditional industrial robots relied on rigidity, jigs, and fixed paths. That’s efficient for mass production, but brittle for real-world variability. Modern robots, however, sense and adapt. Cameras, depth sensors, and AI models let them align, grasp, and inspect without human supervision.
At Black Coffee Robotics, we’ve worked across both ends of this spectrum, from geometric vision in warehouse docking and welding systems to modern deep learning in assistive robotic arms. Below are some techniques that form the backbone of these systems.

ICP repeatedly pairs the closest points between two clouds and minimizes their distance. It’s precise but highly sensitive to initialization; you need a decent starting guess for it to converge correctly. That initial guess can come from odometry, fiducial markers, or another perception stage.
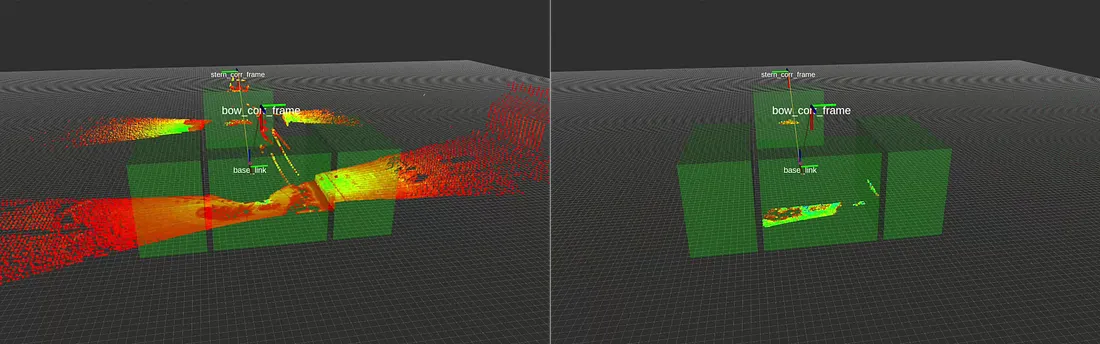
We’ve used ICP for precise docking of autonomous mobile robots (AMR), where the docking station geometry is known a priori. By fusing a 3D depth scan with the known model, the robot aligns to within millimeters before charging. It’s also been useful for part alignment in automated welding and assembly lines.
RANSAC identifies shapes in imperfect data by iteratively testing random samples against a geometric locus until a best-fit emerges. It’s robust to outliers and widely used to extract planes or surfaces from depth or LiDAR scans.
In one project, we used RANSAC on a pair of 3D LiDAR sensors mounted atop a cargo ship to identify the sea plane, then detect nearby docks and piers, relative to it. The algorithm’s noise tolerance makes it ideal for maritime or outdoor robotics where clean data is rare.

These algorithms detect visual keypoints (corners, textures, or edges) that are invariant to scale and rotation and match them between frames. The resulting correspondences are often visualized as small arrowed links connecting identical features across two images.
While deep learning dominates perception today, feature-based methods remain central to vision-based SLAM (Simultaneous Localization and Mapping). They’re lightweight, require no training, and provide precise geometric relationships, qualities that make them valuable for resource-constrained systems or wherever explainability matters.
We often combine ORB or SIFT, with geometric solvers like PnP or RANSAC, to localize objects in cluttered environments.
YOLO (You Only Look Once) remains one of the most influential perception models, originally propelled by the self-driving car industry and now common in warehouse robotics. It performs real-time object detection but is limited by its training dataset, models trained on poor or biased data perform inconsistently.
We’ve used YOLO for assistive robotic arms to identify door handles, fridge knobs, and food items; low-class-count scenarios where the environment is semi-structured and the objects are known ahead of time.

ClipSeg performs zero-shot, text-prompted segmentation producing coarse masks without task-specific training. SAM2 is a high-precision segmenter that converts sparse hints (points, boxes, or a rough ClipSeg mask) into crisp instance boundaries and can maintain consistent masks across video.
We’ve used ClipSeg for coarse localization of known parts in construction and interior assembly where many object types exist, but only a few are relevant to each task. It reduces the need to train and maintain separate models for every class.

These large models integrate perception and control, turning high-level instructions (“pick the red block”) into executable actions. They’re still mostly research-grade, but early results suggest their promise for general-purpose manipulation. Over time, such systems could replace manually tuned perception pipelines.
We’ve experimented with the OpenVLA model, testing its performance in Isaac Sim on a dishwasher unloading task. Performance is highly dependent on the training data and environment complexity; but it shows potential for simplifying robot programming.
Traditional welding robots depend on precise fixturing and pre-programmed paths, which can be inflexible and error-prone when parts are misaligned. In contrast, our vision-guided welding system uses a wrist-mounted depth camera to localize the workpiece, enabling adaptive path execution that meets specific weld requirements.
Validated in Isaac Sim, this approach eliminates manual teaching and tolerates part placement errors; each weld is driven by perception rather than static programming.
The target object point cloud is extracted using ClipSeg and SAM2 on multiple images from different viewpoints.

The segmented point cloud is aligned with the reference CAD model using Iterative Closest Point (ICP), ensuring millimeter-level accuracy.
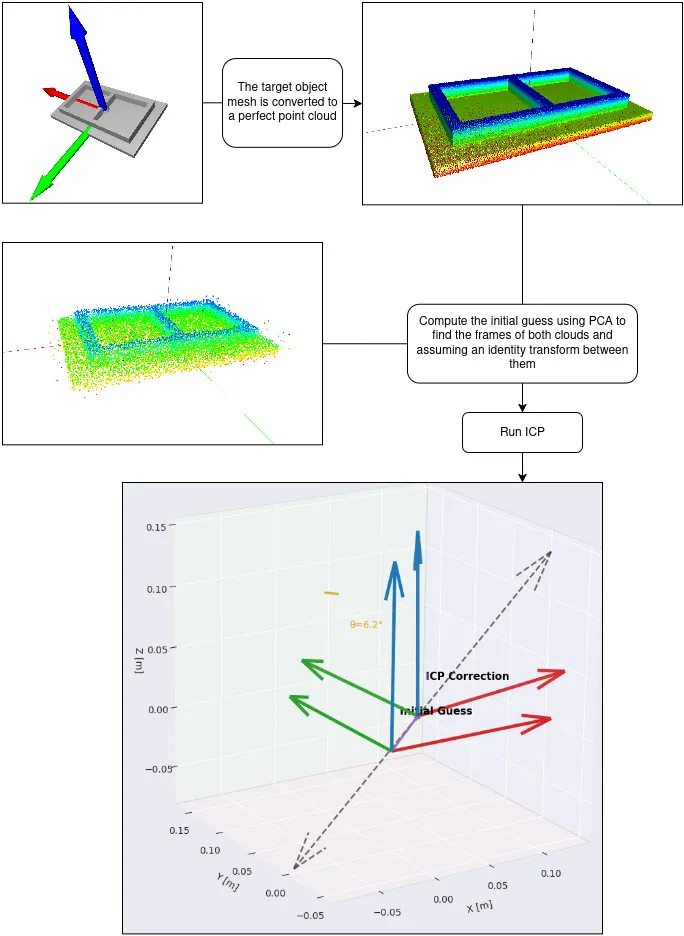
With the part precisely localized, the robot generates and executes the weld path tailored to the actual part position.
From precise geometric alignment to zero-shot understanding, perception has evolved from engineered rules to learned intelligence. Techniques like ICP and RANSAC continue to underpin high-precision tasks, while YOLO and ClipSeg unlock adaptable perception for unstructured environments.
At Black Coffee Robotics, we’ve worked across this full spectrum, combining geometric determinism with modern AI to make robots more flexible, faster to deploy, and easier to maintain.

.webp)
contact@blackcoffeerobotics.com
India, USA